计算机视觉领域的 Alignment Module 设计
目标:将视觉特征与文本或其他模态的特征空间对齐,以实现多模态理解或提升视觉推理能力。
FaithDiff
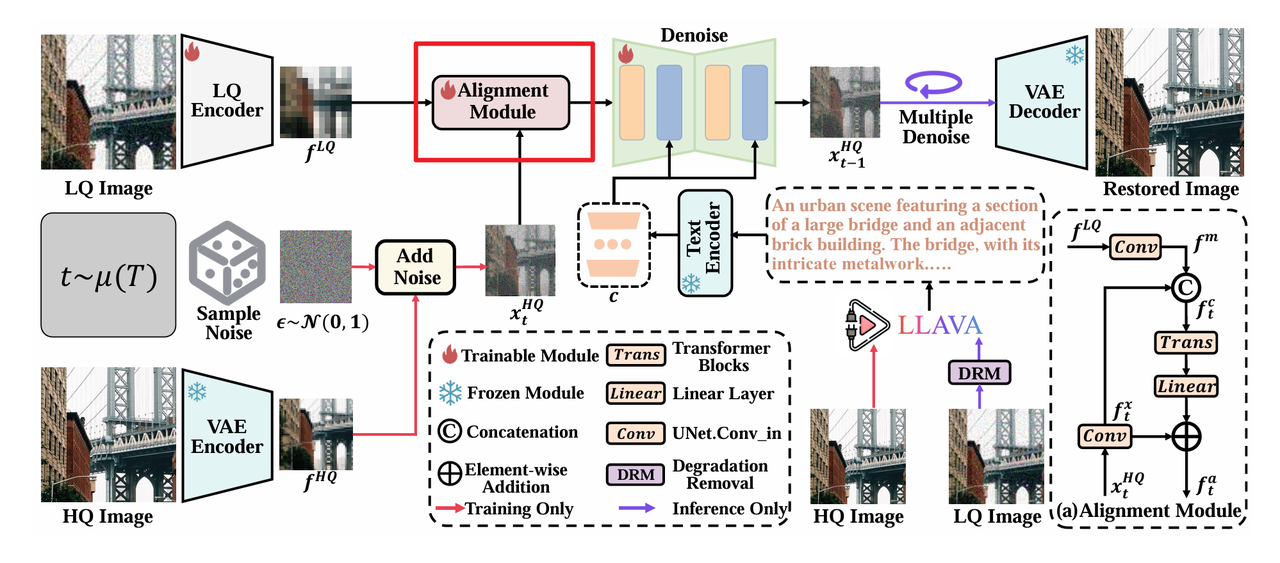
为了能够更好的在生成过程中补充 LQ 图像信息,需要将 LQ 信息注入到模型的生成过程中,但是由于 LQ 图像和 noisy latnet $x_t^{HQ}$ 之间存在 gap,直接相加是不大合理的,所以设计 Alignment Module 将 LQ 图像和 $x_t^{HQ}$ 进行对齐,然后输入到模型中。
具体来说,FaithDiff 中的 Alignment Module 设计如下:
其中 $\mathcal{T}$ 是 Transformer Block, 对应的 Alignment Module 的代码位置
IP-Adapter
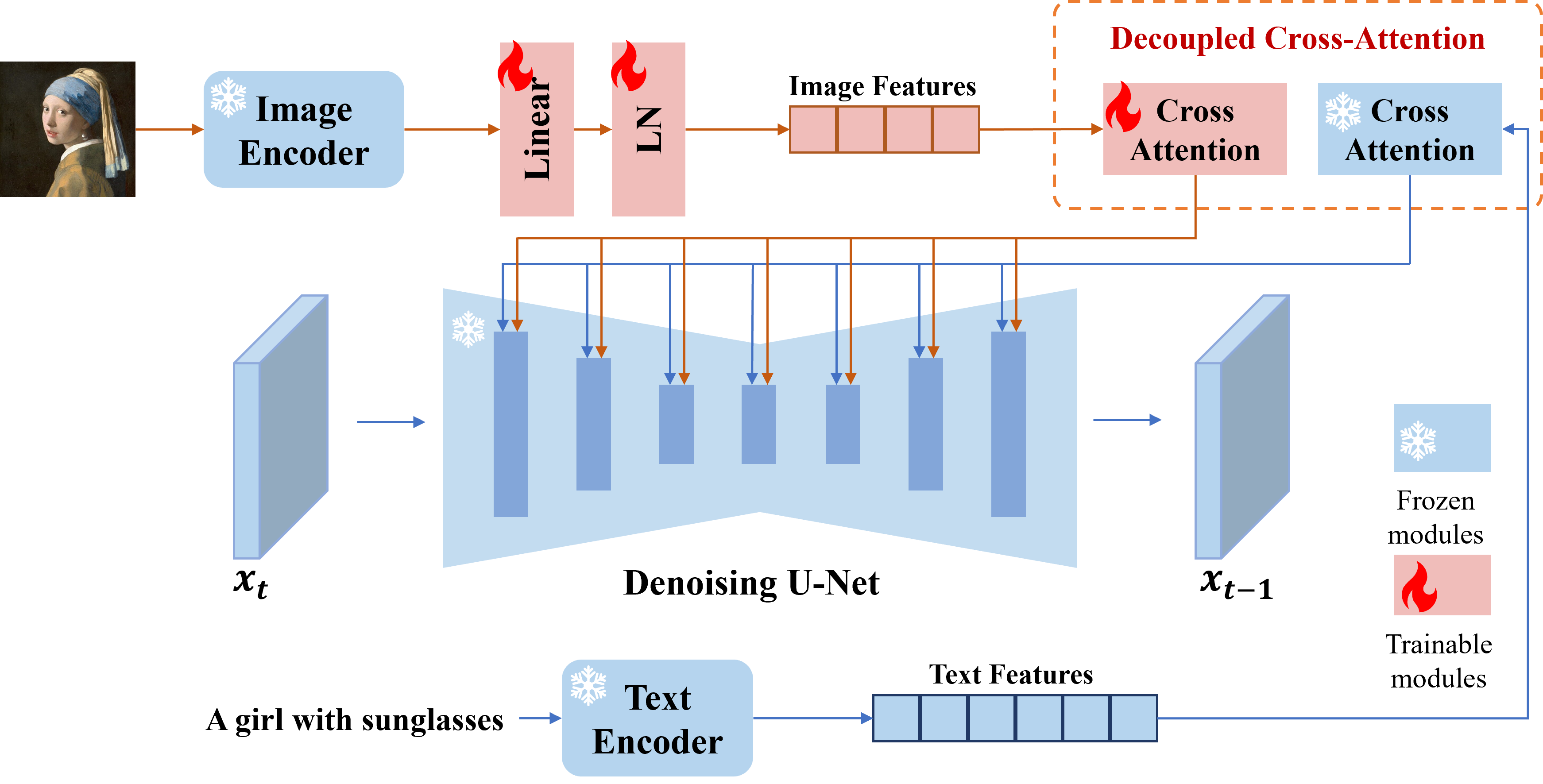
IP-Adapter 通过解耦的两个 Cross-Attention 分别融合图像信息和文本信息,其中图像信息通过 Image-Conditioned Attention 进行融合,文本信息通过 Text-Conditioned Attention 进行融合。这种方式不会让图像和文本信息相互干扰,在信息传递的过程中可以依次提取所需要的图像和文本信息。
DAEFR
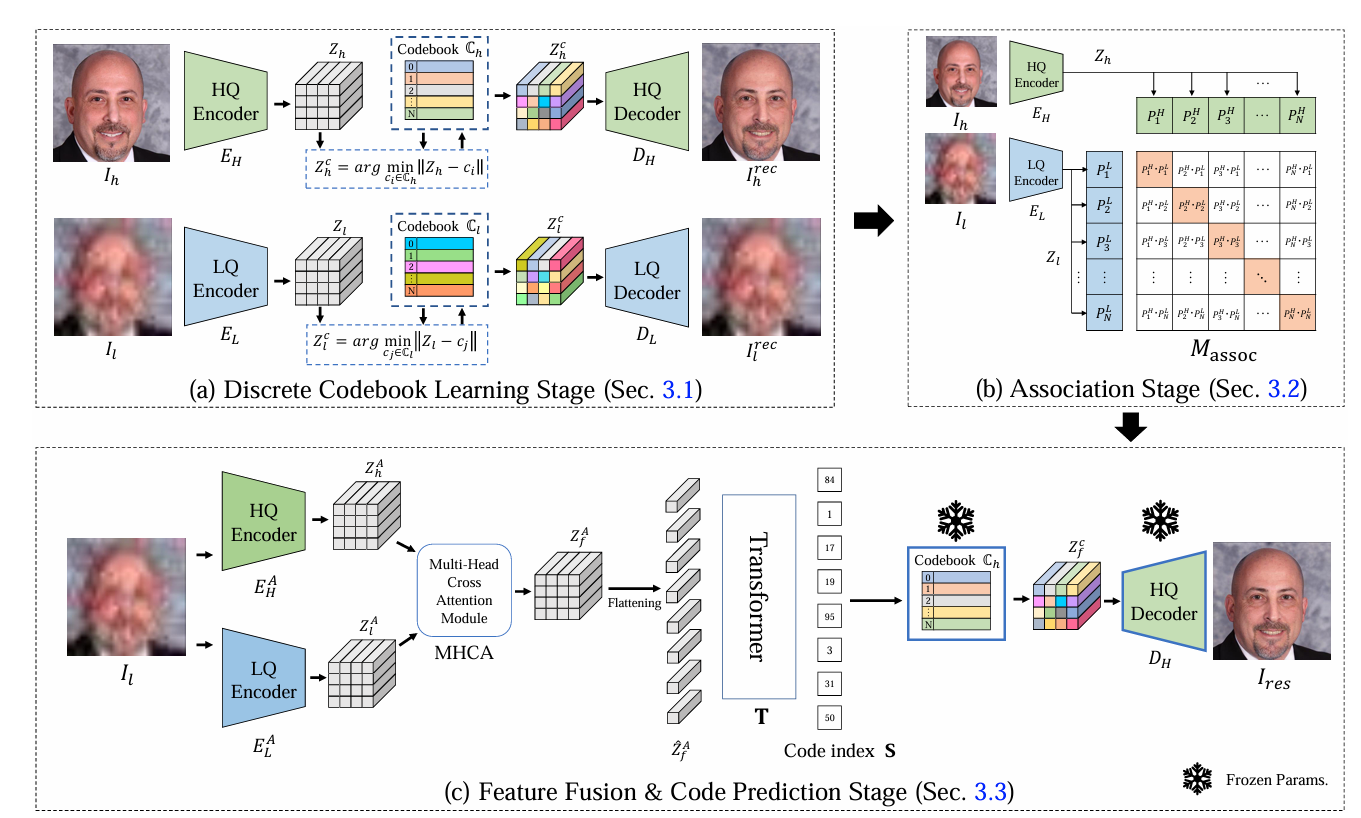
DAEFR 采用 CLIP 的方式,在 (b) Association Stage 对齐 LQ 和 HQ,后续采用 Attention 机制将 LQ 和 HQ 信息进行融合。