情况一:LQ = Low-Quality (低质量)
目标:训练一个编码器(Encoder),使其能够从低质量、有损、模糊或带噪点的输入(如低分辨率图片、压缩过的音频)中提取出稳定、鲁棒的核心特征。
应用场景:图像超分辨率 (Super-Resolution)、图像修复 (Image Restoration)、人脸增强 (Face Enhancement)、去噪 (Denoising) 等。
案例 1: 《SUPIR》
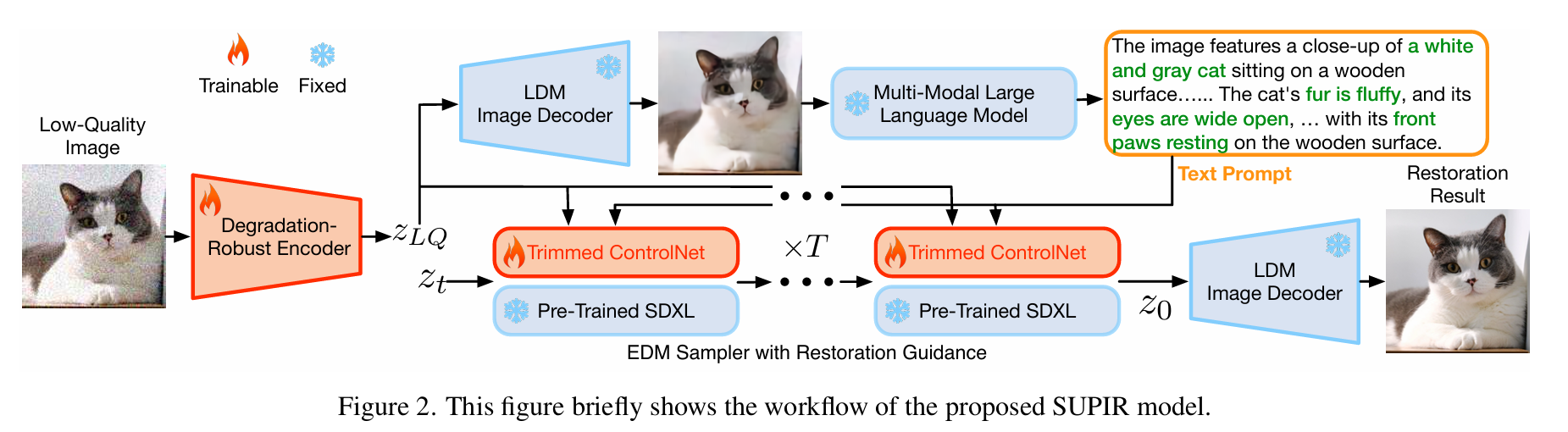
在 SUPIR 中,为了确保低质量图像能够被正确映射到与预训练 SDXL 相同的潜在空间,作者提出了训练一个抗退化编码器(Degradation-Robust Encoder)。SDXL 的扩散生成过程在潜在空间中进行。图像首先通过预训练的编码器映射到潜在空间。为了有效利用预训练的 SDXL,低质量图像 也应该被映射到相同的潜在空间。由于原始编码器没有在低质量图像上训练,直接使用它进行编码会影响模型对低质量图像内容的判断,进而产生误导性的人工制品作为图像内容。训练一个抗退化编码器 ,通过最小化损失函数使其对退化具有鲁棒性:
其中:
- $\mathcal{E}_{dr}$ 是待微调的抗退化编码器
- $\mathcal{D}$ 是固定的解码器
- $x_{GT}$ 是真实图像(ground truth)
这样训练出的编码器能够将低质量图像编码到与高质量图像相同的潜在空间中,确保后续扩散过程的有效性。
案例 2: 《PASD》
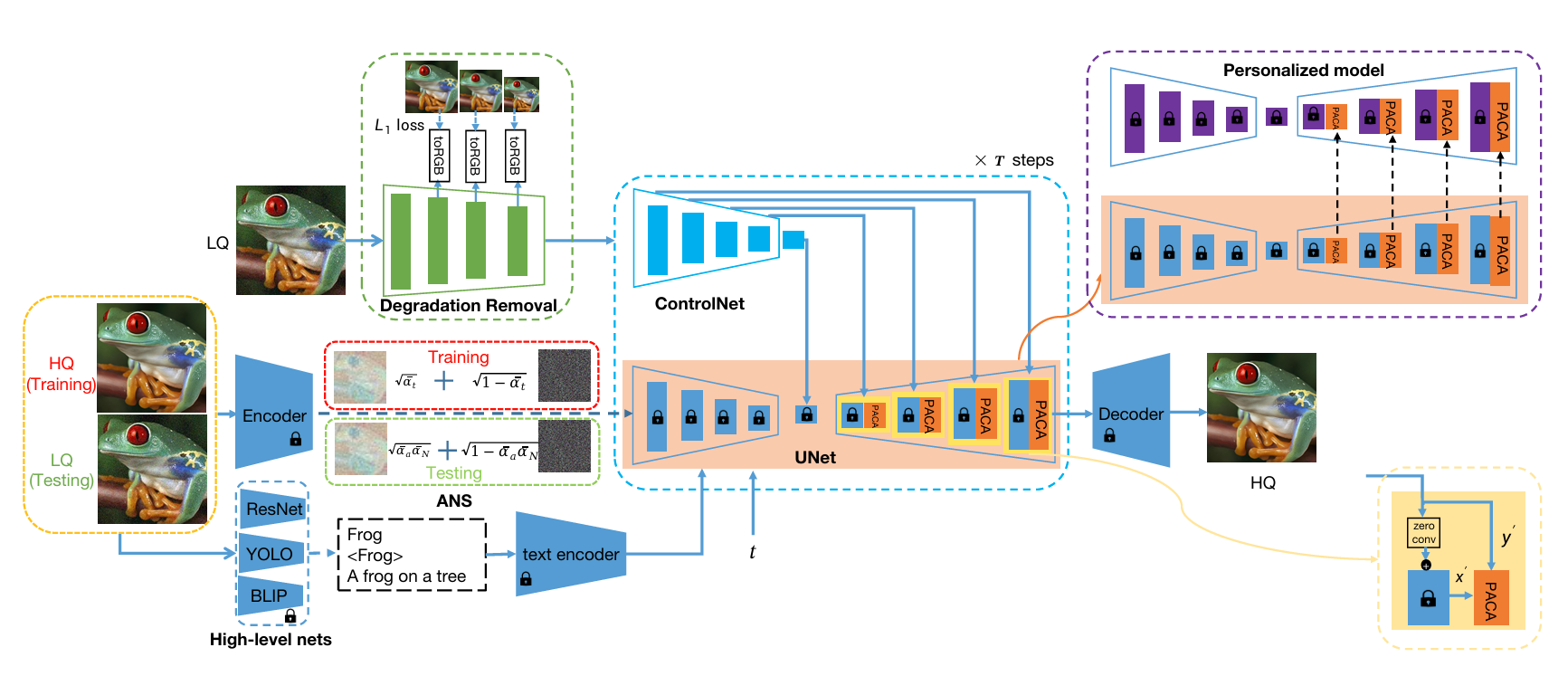
真实世界的低质量图像通常受到复杂且未知的降解影响。因此,作者采用一个降解去除模块来减少降解的影响,并从低质量图像中提取“干净”的特征以控制扩散过程。如图 2 所示,作者采用金字塔网络来提取输入低质量图像的 1/2、1/4 和 1/8 缩放分辨率的多尺度特征图。直观地,这些特征可以用于尽可能接近地逼近相应尺度的高质量图像,以便后续的扩散模块可以专注于恢复真实的图像细节,减轻区分图像降解的负担。因此,作者通过采用卷积层“toRGB”将每个单尺度特征图转换为高质量 RGB 图像空间,引入中间监督。作者在每个分辨率尺度上应用 L1 损失,以强制该尺度的重建接近于高质量图像的相应尺度:
其中:
- $I_{s}^{HQ}$ 是尺度 s 上的高质量真实值
- $I_{s}^{ISR}$ 是尺度 s 上的 ISR 输出
案例 3: 《SeeSR》
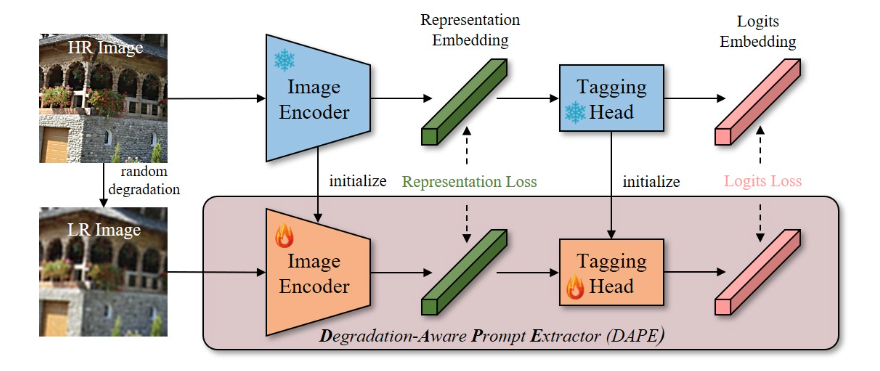
DAPE 是从预训练的标签模型(如 RAM)微调而来的。如图 2(a) 所示,高分辨率图像 $x$ 通过一个冻结的标签模型输出表示嵌入 $f^{HR}$ 和 logits 嵌入 $g^{HR}$,作为监督 DAPE 训练的锚点。低分辨率图像 $y$ 是通过对 $x$ 应用随机降级获得的,它们被输入到可训练的图像编码器和标签头中。为了使 DAPE 对图像降级具有鲁棒性,作者强制低分辨率分支的表示嵌入和 logits 嵌入接近高分辨率分支的嵌入。训练目标如下:
其中 $\lambda$ 是平衡参数,$f^{HR}$ 和 $g^{HR}$ 是低分辨率分支的表示嵌入和 logits 嵌入。 是均方误差(MSE)损失,而 是交叉熵损失。通过对齐低分辨率和高分辨率分支的输出,DAPE 学会从损坏的图像输入中预测高质量的语义提示。
案例 4: 《HeroSR》
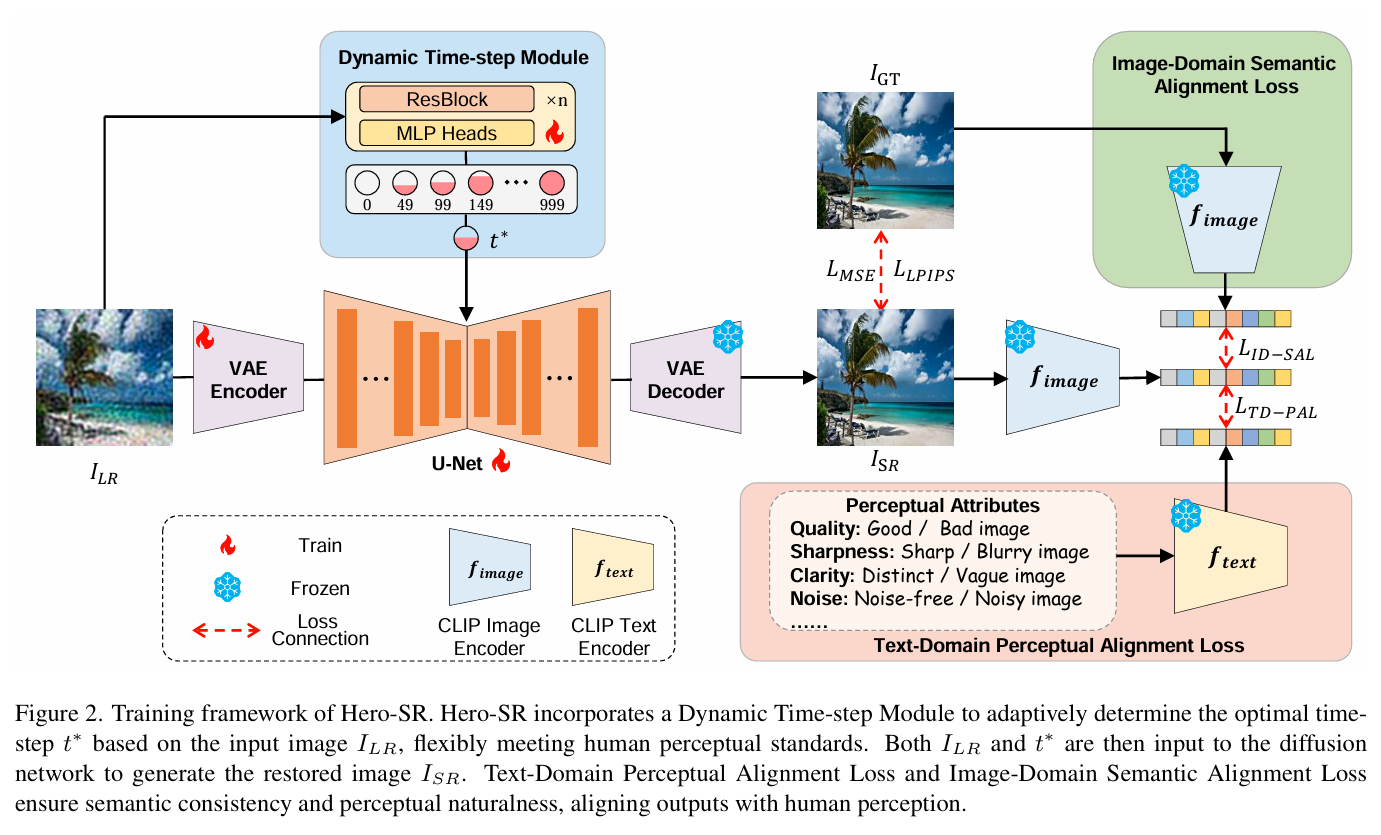
前三种都是有监督,HeroSR 是无监督的方式,采用端到端的优化,让 VAE encoder 和 Unet 注入的 LoRA 层去调制。情况二:LQ = Learned Quantization (学习型量化)
目标:训练一个编码器,其输出的连续特征向量会被一个量化层(Quantization Layer)映射到一组离散的、有限的“码本” (Codebook) 向量上。
应用场景:高效的数据压缩、高质量的生成模型(如 VQ-VAE, VQ-GAN)、学习离散化的数据表征。
案例 1: 《CodeFormer》
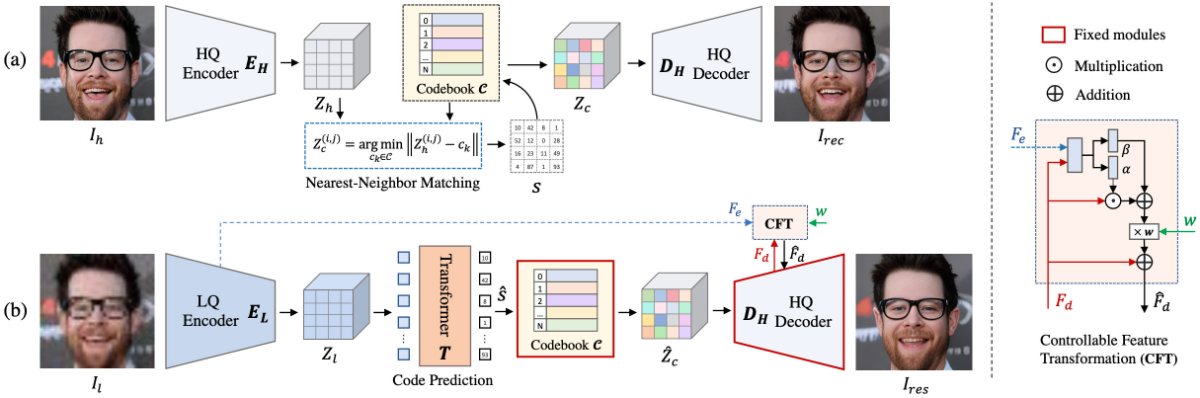
借助训练好的包含 HQ 图像信息的码本,端到端的优化 LQ Encoder。案例 2: 《DAEFR》
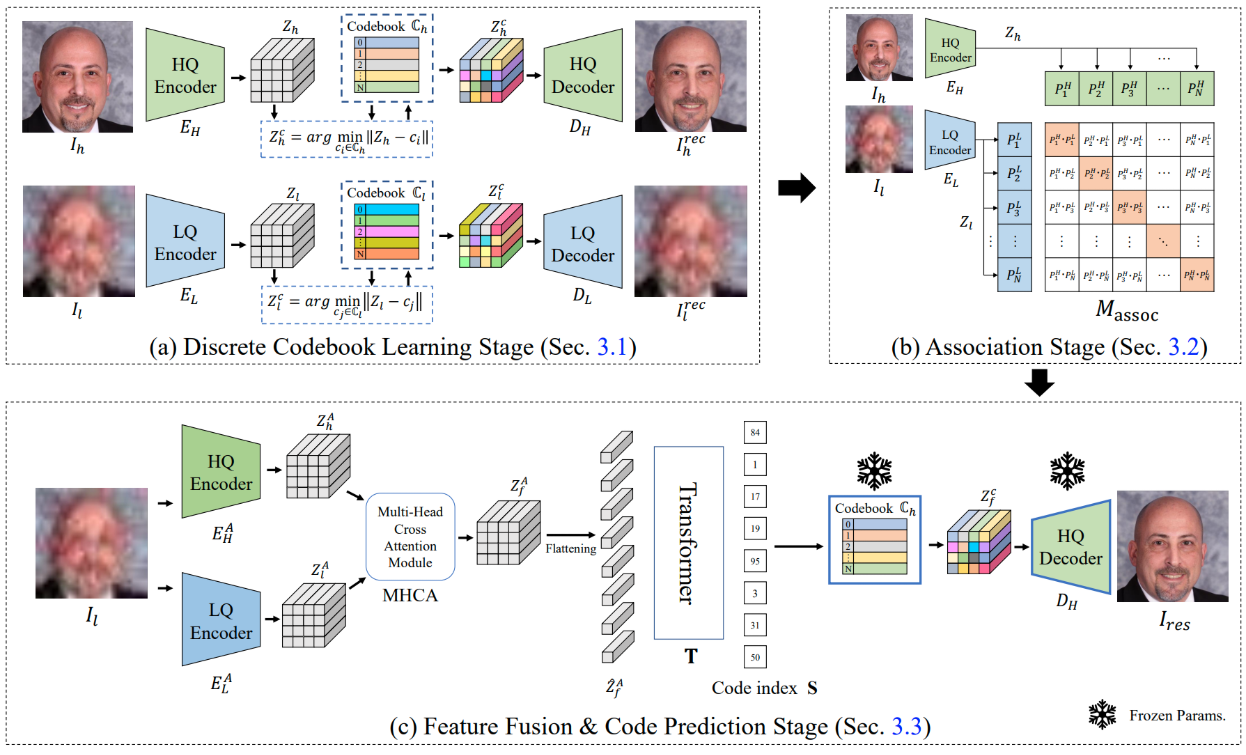
第一阶段 使用 VQ-VAE 预训练训练:
- LQ Encoder → LQ Codebook → LQ Decoder
- 目标:重建 LQ 图像 $x_{LQ}$,得到良好的潜在特征表示。
第二阶段 专注与 HQ 表示的关联:
- 让 LQ Encoder 学习到能预测到 HQ Encoder 的特征边际。
第三阶段:
- LQ Encoder 提供输入特征,经过注意力加 Transformer,预测 HQ 的 code index,最终用 HQ Decoder 重建 HQ 图像。