DCT(离散余弦变换)和 DWT(离散小波变换)是两种在频域上分解面部图像、提取多分辨率纹理特征的有效方法。
DCT 的应用
DCT 通过将图像转换到频域,利用低频分量保留主要图像信息,高频分量表征细节和纹理,从而实现压缩和特征提取。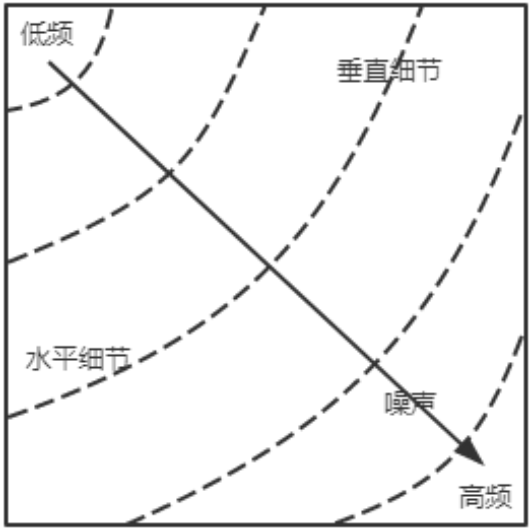

压缩
图像压缩是利用人眼对低频信息比较敏感和对高频信息比较不敏感的原理,对 DCT 变换后的图像,去除部分高频信息,让人眼察觉不到改变,从而实现压缩。如下图所示为保留 DCT 变换后系数的比例,可以看到仅保留左上角 32%的系数基本就可以让人眼看不出来变化。

代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308import torch
import torch.nn.functional as F
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
def dct_2d(x):
"""
2D 离散余弦变换 (DCT)
输入: x - shape (B, C, H, W) 或 (H, W)
输出: DCT 系数
"""
if len(x.shape) == 2:
x = x.unsqueeze(0).unsqueeze(0) # (H, W) -> (1, 1, H, W)
B, C, H, W = x.shape
# 创建DCT基矩阵
n = H
m = W
# DCT-II 基矩阵
def dct_matrix(size):
mat = torch.zeros(size, size)
for k in range(size):
for n in range(size):
if k == 0:
mat[k, n] = np.sqrt(1/size)
else:
mat[k, n] = np.sqrt(
2/size) * np.cos(np.pi * k * (2*n + 1) / (2*size))
return mat
dct_h = dct_matrix(H).to(x.device)
dct_w = dct_matrix(W).to(x.device)
# 应用2D DCT: Y = DxD^T
x_dct = torch.zeros_like(x)
for b in range(B):
for c in range(C):
x_dct[b, c] = torch.mm(torch.mm(dct_h, x[b, c]), dct_w.t())
return x_dct
def idct_2d(x_dct):
"""
2D 逆离散余弦变换 (IDCT)
输入: x_dct - DCT 系数
输出: 重构的图像
"""
B, C, H, W = x_dct.shape
# 创建DCT基矩阵
def dct_matrix(size):
mat = torch.zeros(size, size)
for k in range(size):
for n in range(size):
if k == 0:
mat[k, n] = np.sqrt(1/size)
else:
mat[k, n] = np.sqrt(
2/size) * np.cos(np.pi * k * (2*n + 1) / (2*size))
return mat
dct_h = dct_matrix(H).to(x_dct.device)
dct_w = dct_matrix(W).to(x_dct.device)
# 应用2D IDCT: X = D^T Y D
x_recon = torch.zeros_like(x_dct)
for b in range(B):
for c in range(C):
x_recon[b, c] = torch.mm(torch.mm(dct_h.t(), x_dct[b, c]), dct_w)
return x_recon
def dct_compress_image(image, compression_ratio=0.1):
"""
使用 DCT 压缩图像
参数:
- image: 输入图像 tensor (C, H, W) 或 (B, C, H, W)
- compression_ratio: 保留的DCT系数比例 (0-1)
返回:
- compressed_image: 压缩后的图像
- compression_stats: 压缩统计信息
"""
if len(image.shape) == 3:
image = image.unsqueeze(0) # (C, H, W) -> (1, C, H, W)
B, C, H, W = image.shape
# 分块DCT (8x8块)
block_size = 8
compressed_blocks = []
original_blocks = []
# 确保图像尺寸是8的倍数
pad_h = (block_size - H % block_size) % block_size
pad_w = (block_size - W % block_size) % block_size
if pad_h > 0 or pad_w > 0:
image = F.pad(image, (0, pad_w, 0, pad_h), mode='reflect')
_, _, H, W = image.shape
# 分块处理
for i in range(0, H, block_size):
for j in range(0, W, block_size):
# 提取8x8块
block = image[:, :, i:i+block_size, j:j+block_size]
original_blocks.append(block.clone())
# DCT变换
dct_block = dct_2d(block)
# 压缩: 保留左上角的低频系数
keep_size = int(block_size * block_size * compression_ratio)
mask = torch.zeros_like(dct_block)
# 创建zigzag扫描模式保留最重要的系数
for b in range(B):
for c in range(C):
coeffs = dct_block[b, c].flatten()
# 按幅值排序,保留最大的系数
_, indices = torch.topk(torch.abs(coeffs), keep_size)
mask_flat = torch.zeros_like(coeffs)
mask_flat[indices] = 1
mask[b, c] = mask_flat.reshape(block_size, block_size)
# 应用压缩掩码
compressed_dct = dct_block * mask
# 逆DCT重构
reconstructed_block = idct_2d(compressed_dct)
compressed_blocks.append(reconstructed_block)
# 重组图像
compressed_image = torch.zeros_like(image)
block_idx = 0
for i in range(0, H, block_size):
for j in range(0, W, block_size):
compressed_image[:, :, i:i+block_size, j:j +
block_size] = compressed_blocks[block_idx]
block_idx += 1
# 移除填充
if pad_h > 0 or pad_w > 0:
compressed_image = compressed_image[:, :, :H-pad_h, :W-pad_w]
# 计算压缩统计
original_size = image.numel() * 32 # 假设32位浮点
compressed_size = original_size * compression_ratio
# 计算PSNR
mse = F.mse_loss(compressed_image.squeeze(0), image.squeeze(0))
psnr = 20 * torch.log10(1.0 / torch.sqrt(mse)) if mse > 0 else float('inf')
compression_stats = {
'original_size': original_size,
'compressed_size': compressed_size,
'compression_ratio': compression_ratio,
'size_reduction': (1 - compression_ratio) * 100,
'psnr': psnr.item(),
'mse': mse.item()
}
return compressed_image.squeeze(0), compression_stats
def visualize_compression_comparison(original, compression_ratios, save_path=None):
"""
可视化不同压缩比例的对比效果,同排显示
"""
num_ratios = len(compression_ratios)
fig, axes = plt.subplots(1, num_ratios + 1, figsize=(4*(num_ratios+1), 4))
# 转换原始图像为numpy数组
if isinstance(original, torch.Tensor):
original_np = original.permute(1, 2, 0).cpu().numpy()
else:
original_np = original
# 归一化到[0,1]
original_np = np.clip(original_np, 0, 1)
# 显示原始图像
axes[0].imshow(original_np)
axes[0].set_title('original image', fontsize=12)
axes[0].axis('off')
# 对每个压缩比例进行压缩并显示
for i, ratio in enumerate(compression_ratios):
compressed_img, stats = dct_compress_image(original, compression_ratio=ratio)
# 转换为numpy数组
if isinstance(compressed_img, torch.Tensor):
compressed_np = compressed_img.permute(1, 2, 0).cpu().numpy()
else:
compressed_np = compressed_img
compressed_np = np.clip(compressed_np, 0, 1)
# 显示压缩图像
axes[i+1].imshow(compressed_np)
axes[i+1].set_title(f'compression ratio: {ratio}\nPSNR: {stats["psnr"]:.1f}dB', fontsize=10)
axes[i+1].axis('off')
plt.tight_layout()
if save_path:
plt.savefig(save_path, dpi=300, bbox_inches='tight')
plt.show()
def visualize_compression(original, compressed, stats, save_path=None):
"""
可视化压缩结果
"""
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
# 转换为numpy数组用于显示
if isinstance(original, torch.Tensor):
original = original.permute(1, 2, 0).cpu().numpy()
compressed = compressed.permute(1, 2, 0).cpu().numpy()
# 归一化到[0,1]
original = np.clip(original, 0, 1)
compressed = np.clip(compressed, 0, 1)
# 原始图像
axes[0].imshow(original)
axes[0].set_title('Original Image')
axes[0].axis('off')
# 压缩图像
axes[1].imshow(compressed)
axes[1].set_title(
f'Compressed Image (Ratio: {stats["compression_ratio"]})')
axes[1].axis('off')
# 差异图像
diff = np.abs(original - compressed)
im = axes[2].imshow(diff)
axes[2].set_title(f'Difference Image (PSNR: {stats["psnr"]:.2f}dB)')
axes[2].axis('off')
plt.colorbar(im, ax=axes[2])
plt.tight_layout()
if save_path:
plt.savefig(save_path, dpi=300, bbox_inches='tight')
plt.show()
# 打印统计信息
print(f"压缩统计:")
print(f"- 压缩比例: {stats['compression_ratio']}")
print(f"- 尺寸减少: {stats['size_reduction']:.1f}%")
print(f"- PSNR: {stats['psnr']:.2f} dB")
print(f"- MSE: {stats['mse']:.6f}")
# 示例使用
def demo_dct_compression():
"""
DCT 压缩演示
""" # 创建示例图像或加载图像 # 这里创建一个简单的测试图像
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 生成测试图像
test_image = torch.rand(3, 256, 256).to(device)
# 或者从文件加载图像
from torchvision import transforms
img = Image.open(
'/home/wangj928/data/CelebA_HQ/Img/celeba-hq/celeba-512/000004.jpg')
transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor()
])
test_image = transform(img).to(device)
print("开始DCT压缩...")
# 测试不同的压缩比例
compression_ratios = [0.05, 0.1, 0.2, 0.3, 0.5]
# 使用新的可视化函数显示同排对比
visualize_compression_comparison(
test_image,
compression_ratios,
save_path='dct_compression_comparison.png'
)
# 也可以单独显示每个压缩结果的详细信息
for ratio in compression_ratios:
print(f"\n压缩比例: {ratio}")
compressed_img, stats = dct_compress_image(
test_image, compression_ratio=ratio)
# 可视化结果
visualize_compression(
test_image,
compressed_img,
stats,
save_path=f'dct_compression_{ratio}.png'
)
if **name** == "**main**":
demo_dct_compression()去噪
图像去噪是利用噪声在 DCT 图像中的分布特性(噪声一般为高频信息,DCT 变换后频谱的右下角),基本的方法就是去除 DCT 变换后图像的右下角信息,类似图像压缩。增强
基本原理就是增强高频信息(与去噪相反),最简单的方法就是对高频信息乘以一个大于 1 的数。当然这样也会增强噪声。DCT 图像增强仅对细节进行了增强,图像整体亮度对比度还需结合其他方法。
DCT 在面部图像中的应用
面部图像中,DCT 能够有效压缩图像数据,同时突出低频区域的结构特征,用作人脸识别和纹理分析的特征向量。这些低频系数中包含了人脸的主要信息,而高频系数则对应于面部的纹理细节.
DWT 在多分辨率纹理提取中的优势
DWT 分解面部图像为多尺度的子频带,包括低频(LL)和三个高频细节(LH、HL、HH)分量。通过多层小波分解,DWT 能同时获取图像的粗略结构和细节纹理,实现多分辨率分析。这种方法特别适合于人脸图像的纹理提取和重建,能有效保留面部轮廓和边缘特征,同时在不同分辨率层级捕捉局部纹理变化,被广泛应用于面部超级分辨率重建和特征提取.
清晰的图像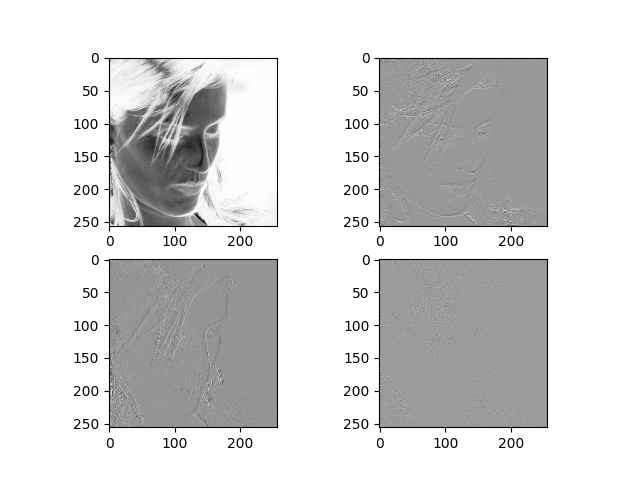
Wider 数据集中的带有噪声的人脸图像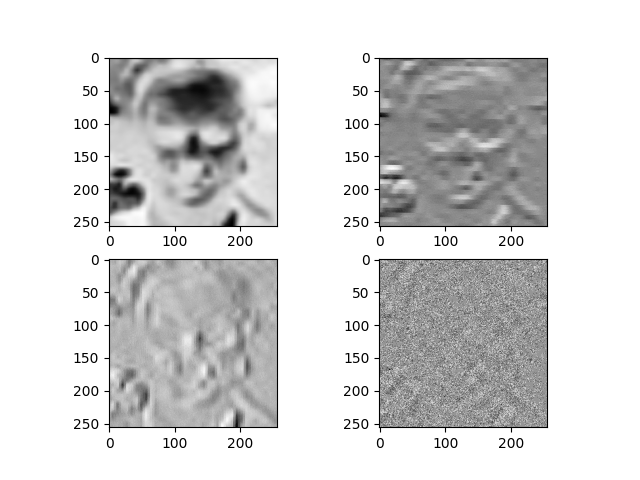
代码
1 |
|